Was ist statistische Datenanalyse?
Moderne Messaufbauten erzeugen enorme Datenmengen – doch reine Rohdaten erzählen selten die ganze Geschichte. Statistische Analyse hilft dabei, diese Daten in ein klares, aussagekräftiges Bild zu verwandeln: Sie fasst Ergebnisse sinnvoll zusammen, deckt Muster auf und ermöglicht sogar Vorhersagen über zukünftiges Verhalten. Im Folgenden erklären wir die Grundlagen der statistischen Datenanalyse und werfen einen Blick auf die statistischen Werkzeuge in unserer Messsoftware OXYGEN.
Was versteht man unter statistischer Datenanalyse?
Statistische Datenanalyse bezeichnet den Prozess, Messdaten zu untersuchen, zu transformieren und zu interpretieren, um Muster zu erkennen, Schwankungen zu quantifizieren und fundierte Entscheidungen zu treffen. Statt sich auf Einzelwerte oder eine rein visuelle Beurteilung zu verlassen, liefert die Statistik eine mathematische Grundlage dafür, wie sich Systeme tatsächlich verhalten.
Obwohl es unzählige statistische Methoden gibt, lassen sich die meisten zwei grundlegenden Kategorien zuordnen:
- Deskriptive Statistik: Sie beschreibt und fasst die wichtigsten Merkmale eines Datensatzes zusammen. Dazu gehören z. B. Mittelwerte, Streuungen, Bereiche, Perzentile oder Verteilungen – also alles, was zeigt, was die Daten widerspiegeln.
- Inferenzstatistik: Sie geht einen Schritt weiter: Auf Basis von Wahrscheinlichkeiten, Modellen und Stichproben werden Rückschlüsse über ein größeres System gezogen. Damit lassen sich Vorhersagen treffen, Parameter schätzen oder Hypothesen prüfen.
| Aspekt | Deskriptive Statistik | Inferenzstatistik |
| Ziel | Beschreibt beobachtete Daten | Zieht Schlussfolgerungen oder macht Vorhersagen über beobachtete Daten hinaus. |
| Typische Ergebnisse | Mittelwert, Median, Min/Max, Standardabweichung, Perzentile, Verteilungen | Konfidenzintervalle, Hypothesentests, Wahrscheinlichkeiten, Regressionsmodelle |
| Beispiele | Histogramme, Korrelationen, Boxplots, einfache Regressionen | Bayessche Methoden, t-Tests, Chi-Quadrat, komplexe Regressionen, Vorhersagemodelle |
| Datengrundlage | Gesamter Datensatz | Stichprobe genügt |
| Risiko | Gering – rein beschreibend | Höher – basiert auf Wahrscheinlichkeiten |
| Annahmen | Wenige, datengetrieben | Abhängig von statistischen Modellen |
| Typische Anwendungen | Trends erkennen, Signale zusammenfassen | Systemverhalten vorhersagen, Leistungsgrenzen schätzen |
Tab. 1: Grundlegender Vergleich zwischen deskriptiver und inferenzieller Statistik
Warum und wo wird statistische Analyse eingesetzt?
Immer dann, wenn Daten interpretiert, verglichen oder zur Entscheidungsfindung genutzt werden müssen, ist statistische Analyse hilfreich. Während Prozesse in der Theorie stabil und störungsfrei sein sollten, zeigt die Realität etwas anderes: Rauschen, Schwankungen, Umwelteinflüsse und dynamisches Verhalten beeinflussen jede Messung. Statistik hilft, diese Komplexität verständlich zu machen.
Je nach Branche kommen unterschiedliche Methoden zum Einsatz:
Automotive Testing
- Vergleich wiederholter Manöver mithilfe von Perzentilen
- Bewertung von NVH- und Vibrationsverhalten über RMS und Standardabweichung
- Analyse von Bremsverhalten mit Min/Max- und Zeitreihenstatistiken
Power & Energy
- Langzeitstabilität von Stromnetzen über gleitende Mittelwerte
- Auswertung von Lastzyklen (Min/Max/Avg pro Zyklus)
- Erkennen ungewöhnlicher Zustände über Histogramme und Verteilungen
Aerospace & Defense
- Bewertung von Strukturbelastungen mit Spitzenwerten
- Bayessche Abschätzung von Ausfallwahrscheinlichkeiten
- Analyse von Vibrationen mit spektralen und Varianz-basierten Kennwerten
Manufacturing & Quality Control
- Überwachung der Prozessstabilität über Standardabweichungen und Kontrollgrenzen
- Erkennen von Ausreißern via Boxplots oder Perzentilbereichen
- Chargenvergleiche über Korrelationen oder einfache Hypothesentests
Research & Development
- Untersuchung von Parameterbeziehungen mittels Regression und Korrelation
- Identifikation von Rauschmustern über Verteilungen oder RMS-Werte
- Validierung theoretischer Annahmen durch Hypothesentests
Langzeit- und Felddatenanalyse
- Zusammenfassung riesiger Datenmengen zu aussagekräftigen Kennzahlen
- Erkennen langsamer Degradationsprozesse über gleitende Mittelwerte
- Identifikation seltener Ereignisse via Histogramme oder Grenzwertüberwachung
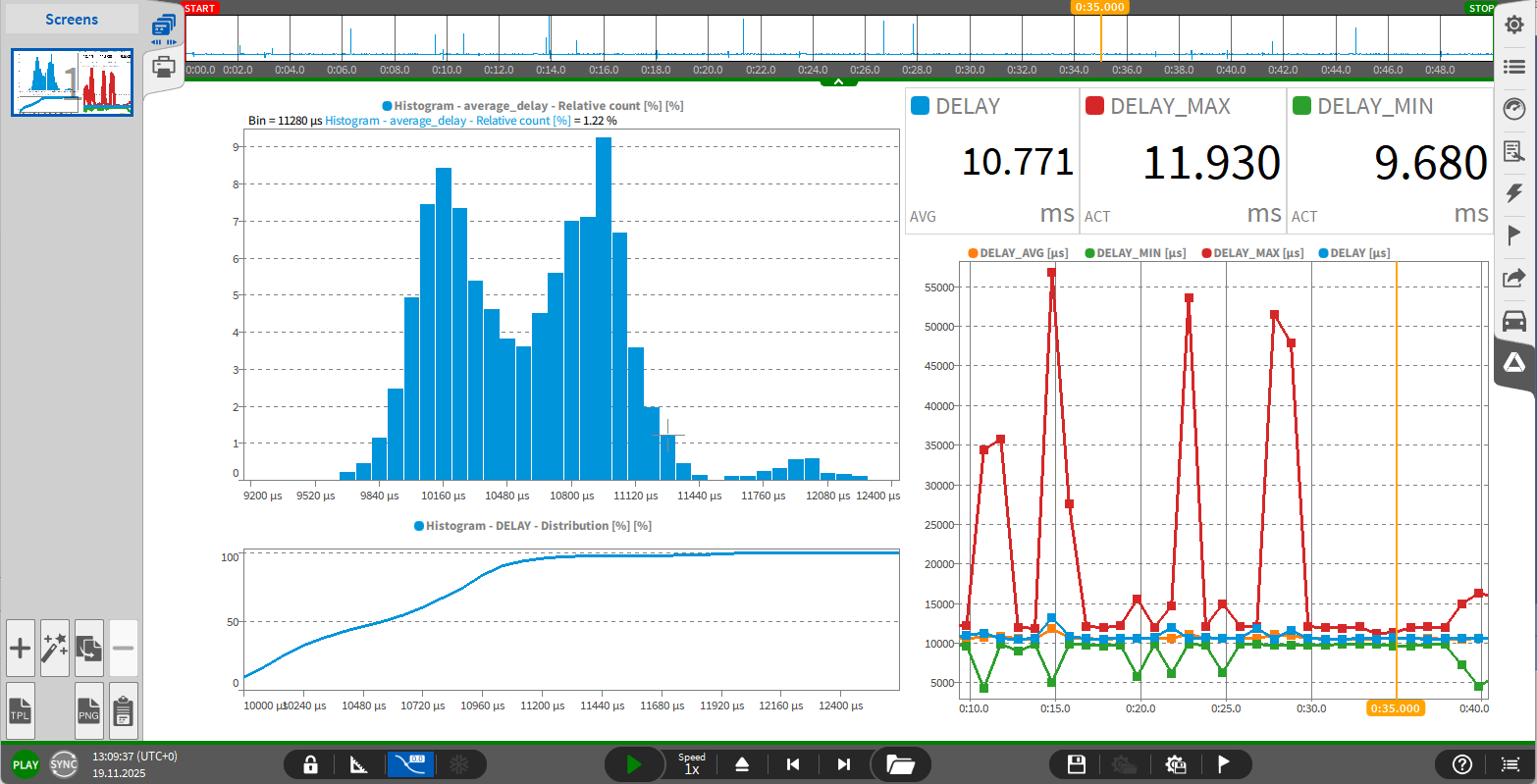
Abb. 1: Statistische Auswertung der Verzögerung bei der Netzwerkübertragung mittels OXYGEN
Welche Optionen bietet OXYGEN zur statistischen Datenanalyse?
Unsere Messsoftware OXYGEN stellt eine breite Palette an Analysewerkzeugen bereit – von einfachen Frequenzbewertungen bis hin zu anspruchsvollen Leistungsanalysen oder Shock-Response-Berechnungen.
Im Bereich der Statistik bietet OXYGEN umfassende Funktionen, insbesondere für deskriptive und zusammenfassende Auswertungen. Dazu gehören:
- Basiskennwerte (Mean, Min, Max, Standardabweichung usw.)
- Block- und gleitende Statistik
- Getriggerte Statistik für ereignisbasierte Auswertung
- Statistik über gesamte Messungen
- Array-Statistik
- Histogramme
- Korrelation
- … sowie weitere Funktionen für professionelle Test- und Messabläufe









